Page de code

Cet article est une ébauche concernant l’informatique.
Vous pouvez partager vos connaissances en l’améliorant (comment ?) selon les recommandations des projets correspondants.
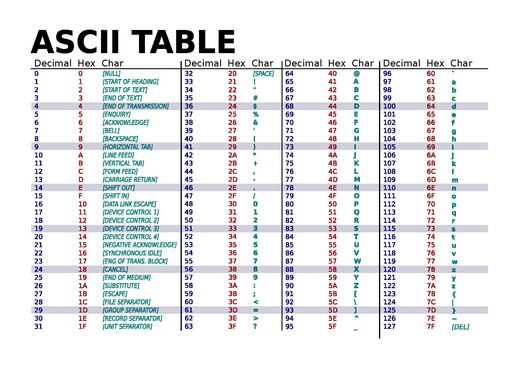
Une page de code est un standard informatique qui vise à donner un numéro à chaque caractère d'une langue, ou de quelques langues proches. Elle constitue donc une méthode simple de pratiquer du codage des caractères.
Le plus souvent elle associe un caractère ou symbole graphique à chacune des 256 valeurs que peut avoir un octet. L'ensemble des langues de la planète utilise des milliers de caractères ou de symboles graphiques différents, un même octet représente donc un caractère/symbole différent, selon la page de code utilisée par le système informatique. Les pages de code introduisent donc des incompatibilités entre documents de langues différentes (exemple français-russe) ou de systèmes informatiques différents (exemple DOS-Windows).
Alors que l'ASCII a été inventé en 1961, les premières pages de code ont été définies et nommées ainsi par IBM autour de l'EBCDIC en 1964[1], la même année où l'union soviétique définissait les pages de code GOST 10859 (en). Par la suite les nouvelles pages de code ont été définies autour de la norme ASCII, sous-ensemble commun à nombre de pages de code. Ces dernières ont eu une meilleure notoriété car elles ont été répandues avec l'essor des "ordinateurs personnels", vers les années 1980-1995.
L'ASCII n'utilise que 7 bits et les ordinateurs modernes (depuis les années 1970) représentent chaque caractère avec au moins 8 bits (un octet), les codes 128 à 255 sont disponibles pour étendre l'ASCII. En conséquence, la signification de ces 128 valeurs correspondait à des caractères différents selon les systèmes. Lors d'échanges de fichiers entre systèmes n'utilisant pas les mêmes pages de code, les caractères non-ASCII (ou non anglais) pouvaient être perdus et les textes devenir incompréhensibles, sauf pour la langue anglaise qui est la seule à pouvoir s'écrire avec les 26 caractères de l'alphabet ASCII non accentués. L'échange de données s'effectuant souvent localement, les problèmes d'incompatibilité étaient minimes.
La démocratisation/massification de la mise en réseau internationale des ordinateurs vers les années 1995-2000, et l'augmentation des échanges internationaux de données textuelles, ont fait naître le besoin d'une unification du codage des caractères afin de dépasser les problématiques des pages de code. En 2010 dans les nouveaux logiciels, les pages de code ont tendance à tomber en désuétude, au profit d'Unicode. Pour des raisons notamment techniques, culturelles, ou économiques, certains logiciels plus anciens continuent cependant à fonctionner avec une logique de pages de code.
Nomenclature des pages de code
[modifier | modifier le code]Pages de code utilisées par DOS
[modifier | modifier le code]- 437 — page de code stockée en ROM de l'IBM PC, aussi appelée page de code des États-Unis
- 720 — alphabet arabe
- 737 — alphabet grec
- 775 — alphabet latin (langues baltes)
- 850 — alphabet latin (langues d’Europe occidentale)
- 852 — alphabet des langues slaves
- 855 — alphabet cyrillique
- 857 — alphabet latin (turc)
- 858 — alphabet latin « Multilingual » avec le symbole de l’euro
- 860 — alphabet latin (portugais)
- 861 — alphabet latin (islandais)
- 862 — alphabet hébreu
- 863 — alphabet latin (français canadien)
- 865 — alphabet latin (danois, norvégien, la seule différence avec la page de code 437 est la lettre Ø et ø à la place de ¥ et ¢
- 866 — alphabet cyrillique (basé sur GOST 19768-87)
- 869 — alphabet grec
- 874 — alphabet thaï
Pages de code utilisées par Windows
[modifier | modifier le code]- 874 — alphabet thaï
- 932 — écritures du japonais
- 936 — chinois simplifié (République populaire de Chine, Singapour)
- 949 — hangeul (coréen)
- 950 — chinois traditionnel (Taïwan, Hong Kong)
- 1200 — Unicode (BMP de l’ISO 10646, UTF-16LE)
- 1201 — Unicode (BMP de l’ISO 10646, UTF-16BE)
- 1250 — alphabet latin (langues d’Europe centrale)
- 1251 — alphabet cyrillique
- 1252 — alphabet latin (langues d’Europe occidentale, remplace la page de code 850)
- 1253 — alphabet grec
- 1254 — alphabet latin (turc)
- 1255 — alphabet hébreu
- 1256 — alphabet arabe
- 1257 — alphabet latin (langues baltes)
- 1258 — alphabet latin (vietnamien)
- 65000 — Unicode (BMP de l’ISO 10646, UTF-7)
- 65001 — Unicode (BMP de l’ISO 10646, UTF-8)
Voir aussi
[modifier | modifier le code]Notes et références
[modifier | modifier le code]- « Code Page Identifiers (Windows) », Windows, Centre de développement - Bureau
